The dominant narrative of the last software cycle was that value migrates up the stack — toward the application, the workflow, the system of record, the seat you sell. That was true for SaaS, where the marginal cost of serving one more user approached zero and durable 75–90% gross margins accrued to whoever owned the interface.
AI inverts it. The center of gravity is moving down the stack, toward the layers with the highest capital intensity, the deepest physical constraints, and the strongest control points: semiconductors and compute, data platforms, open models and the inference engines that run them, and a narrow premium frontier tier. The application layer does not disappear — but it thins. Its margins compress as inference becomes a variable cost of goods, and its multiples bifurcate: the model and the data re-rate upward, the wrapper does not.
Stated plainly: the future is a very large number of open-source models (with inference platforms to run and optimize them), a smaller set of premium models, data platforms, and the semiconductors to power all of it — sitting beneath a thinner application software layer than the SaaS era trained us to expect.

The rotation reverses
This is heretical to how private capital has thought for 20 years. After the dotcom crash, investors fled capital-intensive, cyclical semiconductors and rotated decisively into asset-light cloud and SaaS — 80%+ gross margins, near-zero marginal cost, recurring revenue, and capital efficiency that compounded into the highest multiples in the market. “Software is eating the world” became the organizing thesis of an entire generation of funds; the LP and GP base reorganized around application software, and the semiconductor industry was treated as a low-multiple, cyclical afterthought.
AI reverses the rotation. Capital is flowing back down into the physical, capital-intensive layers the industry spent two decades fleeing — silicon, packaging, power, data infrastructure, and the inference plumbing on top. The most valuable franchise in technology is, again, a chip company; the fastest-growing infrastructure businesses ever recorded are inference and data platforms. The asset-light application layer — the destination of the last rotation — now carries the worst margin structure in the stack. Twenty years of muscle memory points the wrong way.
Framework: value has gravity
Treat the AI stack as five layers and ask one question of each: how easily can the next dollar of value be substituted away? Value, like mass, accumulates where it cannot easily move. Four properties pull value down the stack and hold it there.
- Capital intensity. The base layers cost tens of billions to build, continuously. The four largest hyperscalers are spending at a $500B+ annualized pace on capex, heading toward $600B+ for 2026. Capital is a moat when it is both enormous and perpetually required.
- Physical bottlenecks. Advanced packaging (CoWoS), high-bandwidth memory, and power are hard limits that money cannot relax on a quarterly cadence. Scarcity accrues to whoever controls the constraint.
- Switching cost and inertia. Data has gravity in the original sense: every pipeline, table, and model trained in place raises the cost of leaving. Open weights are the opposite — engineered to be portable — which is exactly why value at that layer shifts from the model to the platform that serves it.
- Replacement risk at the surface. Generic application logic is the most substitutable thing in the stack, because the model can increasingly perform it directly.
The rest of this piece walks the layers from the base up, with the numbers.

Layer 1 — Semiconductors and compute: the densest mass
This is the heaviest layer, and it is getting heavier. In its most recent quarter — ended April 2026 — NVIDIA’s data-center revenue hit $75.2B, up 92% year over year, at a ~75% gross margin: roughly a $300B annualized run-rate, with the current quarter guided to $91B in total revenue. NVIDIA holds about 80% of AI accelerators by revenue. Those are not the economics of a competitive commodity market; they are the economics of a control point.
The demand beneath it is a capex supercycle without parallel in enterprise technology. In Q1 2026 alone, the four largest hyperscalers spent roughly $131B on capex — Amazon $44.2B, Alphabet $35.7B, Microsoft $30.9B, Meta $19.8B — a ~$525B annualized pace, still climbing toward $600B+ of full-year 2026 guidance. Goldman Sachs models $5.3T of cumulative hyperscaler capex from 2025 through 2030.

And it is not only compute. The entire semiconductor industry is in a supercycle: global revenue hit $793B in 2025 (+21% YoY) and is on track to approach $1 trillion in 2026 (WSTS ~$975B, +25%; Gartner higher still), with AI now ~30% of all semiconductor revenue and headed past 50% by 2029. The demand splits into three buckets, and all three are supply-constrained. Compute — logic, GPUs, and accelerators — is the largest: AI accelerators alone scale from ~$80B in 2024 to $280B+ by 2029. Memory is the fastest-moving: HBM demand grew ~130% in 2025 and another ~70% in 2026, conventional DRAM contract prices jumped ~90% quarter-over-quarter in Q1 2026, and AI data centers are absorbing roughly 70% of high-end DRAM. Storage is quietly tightening too: the NAND market reaches ~$65B in 2026, one in five bits now feeds AI, and demand (+20–22%) is outrunning supply (+15–17%) into 2027. When a single end-market reprices DRAM 90% in a quarter and books advanced packaging two years out, the constraint — and the margin — has moved into the physical layer.

Two features make this layer durable rather than merely large. First, the binding constraint has moved from chip design to packaging and power. TSMC’s CoWoS capacity — about 70k wafers/month in 2025, rising toward ~110k in 2026 — is effectively sold out, and NVIDIA has reserved the majority of supply into 2027. Second, more than 10 GW of new AI data-center capacity was announced in 2025, against a packaging base that can support on the order of 18 GW. When the bottleneck is physical, capital intensity is a feature for incumbents and a wall for entrants.
The replacement risk here is real but slow: hyperscaler custom silicon (Google TPU, AWS Trainium, Broadcom ASICs) is growing into a $200B+ accelerator TAM. It compresses NVIDIA’s share over time; it does not move value out of the layer. The mass stays at the bottom.
The real risk at this layer is returns, not revenue. At a $500B-plus annual capex run-rate against accelerators that depreciate over two-to-three-year useful lives, margin durability depends on utilization staying high enough to earn a return on the installed base. That — not competition — is the single largest swing factor beneath the entire stack.
Layer 2 — Open models and inference: abundance at the model, value at the platform
The single most important quantitative story in AI over the past 24 months is convergence. Per the Stanford AI Index, the gap between the best closed model and the best open-weight model on Chatbot Arena fell from 8.04% in January 2024 to 1.70% in February 2025. On MMLU, the 2023 gap of ~17.5 points has effectively closed. DeepSeek R1 showed that frontier-class reasoning does not require nine-figure training budgets; Qwen overtook Llama as the most-downloaded model family on Hugging Face.

The supply side is now effectively infinite. Hugging Face hosts more than 2.2M models, with the catalog doubling in roughly 24 months. When a capability exists in thousands of near-equivalent open variants, the weights themselves stop being the scarce asset. The scarce asset becomes the ability to run them well — throughput, latency, cost per token, routing, caching, fine-tuning, evaluation, and guardrails.
There is a market-structure wrinkle investors should not miss: the open-weight frontier is increasingly non-US. Chinese developers accounted for 17.1% of Hugging Face downloads from August 2024 to August 2025, edging out the US at 15.8%, and Qwen displaced Llama as the most-downloaded family. The commoditizing layer is also the layer least controlled by US incumbents — a supply-chain and policy variable, not only an economic one.
Linux did not capture the value of Linux; Red Hat and the cloud did. The same pattern now applies to open weights — value accrues to the platform that serves them, not the model itself.
This is why the durable business at this layer is the inference and optimization platform, not the open model. The platform sits between abundant open supply and enterprise demand, and monetizes the one thing that does not commoditize: making a portable artifact perform reliably and cheaply in production.
The market is proving this in real time, at a velocity with no precedent in infrastructure software. Fireworks AI disclosed it crossed $800M in annualized revenue in roughly three years — up over 4× year over year. Together AI is rumored to be at a similar scale; Baseten reached ~$600M, up >5X year over year. None of these are model labs — they are the toll roads that make open weights usable in production. When the model itself is free, the company that serves it fastest and cheapest captures the spend.
The math is why. Consider a team serving 50B output tokens a month — a mid-size AI feature. At frontier-API output pricing of ~$10–15 per million tokens, that runs ~$500–750K a month; the same workload on an open model (Llama, Qwen, DeepSeek) served through an inference platform at ~$0.40–1.00 per million costs ~$20–50K — a 90%+ reduction. Below a quality threshold that keeps falling, open-plus-inference wins on cost by an order of magnitude, and the platform that delivers it keeps a slice of the savings as margin. That is the whole business. (Illustrative; actual costs vary with model, context length, and utilization.)
Layer 3 — Premium models: a smaller, real, defensible tier
Convergence compresses the average but not the frontier. A premium tier persists wherever the marginal point of capability — complex agentic tasks, long-horizon reliability, production coding, safety — is worth paying for. Revenue proves it: Anthropic reported ~$47B annualized by May 2026 (from ~$1B at end-2024) and is tracking toward an estimated ~$100B run-rate by year-end; OpenAI — ~$6B at end-2024, ~$20B at end-2025, ~$30B in mid-2026 — is on a path to an estimated ~$60B. More than 1,000 enterprises spend over $1M/year with Anthropic alone.
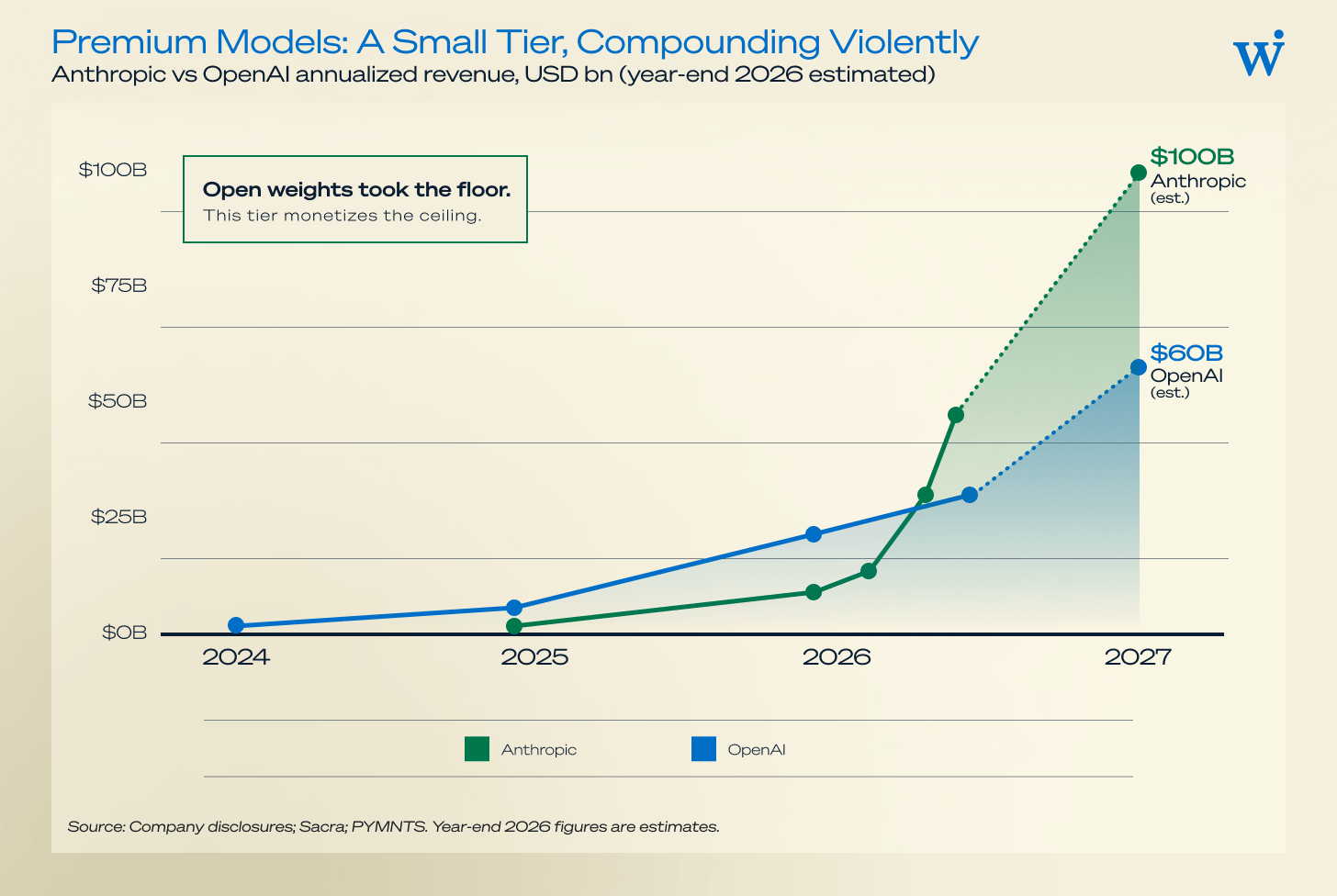
(Both labs report on different revenue bases, and year-end 2026 figures are estimates; treat the absolute numbers as directional and the trajectory as not.)
The strategic point for investors: this is a narrower layer than the 2023 consensus assumed. Open weights have taken the floor; the premium tier monetizes the ceiling. The defensible position is the frontier plus the distribution to reach enterprises — not “a good model,” which is now free and plentiful.
Layer 4 — Data platforms: the gravity well that compounds
If semiconductors are the densest layer, data platforms are the stickiest. This is “data gravity” in its literal form: the cost of moving away rises with every pipeline, table, and ontology built in place.
The numbers show the layer capturing the AI workload directly — and the market paying premium multiples for it. Databricks crossed a $6.9B annualized run-rate growing ~80%, with AI products already ~26% of revenue, valued around $170B privately. Palantir — the operational layer that turns enterprise data into governed decisions — grew revenue 85% year over year in Q1 2026 (its fastest ever) to a ~$6.5B run-rate, with US commercial revenue up 133% and a Rule of 40 of 145%. At a ~$350B market cap, the market pays Palantir a foundation-model-class multiple — roughly 50× revenue — for owning the decision loop that sits on top of data.

Why does value hold here while it leaks at the model layer? Because data is the one input that is both non-substitutable and accretive. Models converge; a company’s proprietary data — and the workflows and ontology built on it — does not. As the model layer commoditizes, the platform that owns the data and the decision loop becomes the durable point of leverage. Note the inversion this implies for the application thesis: the layers commanding the highest multiples — Palantir at ~50× revenue, foundation models at 25–50× — are precisely the ones fused to proprietary data, not the generic software surface.
Layer 5 — The application layer: thinner than the SaaS playbook assumes
Now the top. The thesis is not that applications die; it is that the generic application surface thins, in two measurable ways.
First, margins. Traditional SaaS runs 75–90% gross margins because marginal serving cost approaches zero. AI-native applications run 50–60%, because every query re-runs a model. By ICONIQ’s 2026 data, inference averages ~23% of revenue at scaling AI companies — and, critically, it does not fall with scale the way SaaS COGS did. The thin-wrapper extreme can sit at 25% gross margin. Inference is a structural, variable cost of goods.
Second, multiples. The market is already pricing the bifurcation. Foundation-model companies trade at 25–50× revenue; AI-native platforms at 25–30×; traditional SaaS has compressed to a ~6.7× median (from an 18.6× peak in 2021); and “AI wrappers” sit at 5–8× — at or below legacy SaaS. Value re-rates to the model and the data; it derates at the undifferentiated surface.

This does not mean “don’t invest in applications.” It means the bar moved. A durable application now needs something the model cannot absorb: a proprietary data loop, a system of record, a regulated workflow, real distribution, or outcome-based pricing that converts inference cost into margin. Absent that, the application is a thin layer of prompt-and-glue over a commoditizing model — and the multiple will say so.
The counter-thesis: what would make me wrong
Decisive does not mean unfalsifiable. Three developments could redistribute value back toward the top.
Apps capture the data loop. If the best applications accumulate proprietary interaction data fast enough, they become data platforms in their own right and inherit the gravity. This is the strongest bull case for the application layer, and the reason the system-of-record app is exempt from the thinning.
Vertical integration collapses layers. A premium-model lab that owns inference, builds agents, and sells the application directly could re-internalize value across three layers at once. That concentrates value rather than redistributing it upward — but it does erode the independent inference and app layers.
Inference commoditizes faster than expected. LLMflation — roughly a 10×/year decline in the cost of a unit of intelligence, with median price drops near 200×/year since early 2024 — cuts both ways. If serving becomes nearly free, AI-app gross margins recover toward SaaS norms and the margin half of the thinning thesis weakens. (The multiple half largely holds, because substitutability, not cost, drives it.)

Note the tension: the same cost collapse that pressures the semiconductor and inference layers on price is what could make the application layer’s margin problem temporary. I weight the structural argument above the cost-relief argument, because substitution risk at the surface persists even at zero inference cost.
Implications
For investors. Underwrite control points, not interfaces. The highest-conviction, lowest-substitution positions are: compute and the physical bottlenecks around it (packaging, power, memory); data platforms with proprietary accretion; and the inference/optimization layer that monetizes open-model abundance. In the premium-model tier, underwrite the frontier plus distribution, and size for a narrower-than-consensus winner set. At the application layer, require a data loop or a system of record before paying a software multiple — and assume 50–60% gross margins, not 80%+, until proven otherwise.
For founders. If you are building an application, your job is to manufacture gravity. Own a proprietary data loop, become a system of record, or price on outcomes so that falling inference cost flows to your margin rather than your customer’s savings. “Thin” describes the default, not a sentence.
For incumbents. The capital intensity of the base layers is a moat you can rent but not own. For most enterprises the defensible move is up at the data layer — keeping data, training, and serving in one place — rather than competing on compute or frontier models.
What would confirm — or break — this
Five measurable signals over the next four quarters will tell you whether the heavy stack is holding:
- Hyperscaler capex-to-revenue. If it keeps climbing past ~25–30% of revenue without denting margins, the base layer’s returns thesis holds; if ROIC cracks, the whole stack reprices.
- Inference-platform ARR. Fireworks, Together, and Baseten compounding toward ~$1–2B each confirms value is pooling at the inference layer, not the model.
- The open–closed gap. If it stays inside ~2 points on hard benchmarks (agentic, coding), commoditization of the model layer is locked in.
- AI-app gross margins. If scaling AI apps stay at 50–60% (inference not falling with scale), the thinning thesis holds; a recovery toward 75%+ would weaken it.
- DRAM and HBM pricing. Continued double-digit quarterly price increases mean the physical constraint — and the margin — is still at the base.
Summary: probability-weighted, 3–5 years

The recommendation is consistent across the high-probability branches: position at the base and the data layer, treat the premium-model tier as a narrow high-conviction bet, and hold applications to a higher bar — a data loop or a system of record — before underwriting them at software multiples. Gravity is doing the work. Invest where the mass is.
Sources: NVIDIA Q1 FY2027 results (May 2026); company Q1 2026 earnings (Amazon, Alphabet, Microsoft, Meta); Stanford HAI AI Index 2025; Hugging Face; Epoch AI; Andreessen Horowitz ("LLMflation"); Gartner and WSTS (semiconductor revenue); TrendForce and Counterpoint (DRAM/NAND/HBM); BofA; Databricks and Palantir disclosures; OpenAI, Anthropic, Fireworks AI, Together AI, Baseten (via Sacra / PYMNTS); ICONIQ State of AI 2026; Goldman Sachs; ValueAddVC; SaaS Capital. Private-company revenue run-rates are reported on differing bases; year-end 2026 model-lab figures are estimates.


